Design,
Implementation, and Performance Analysis of the iSCSI Protocol for SCSI over
TCP/IP
ANSHUL CHADDA
ASHISH PALEKAR
Trebia
Networks Inc
33
Nagog Park
Acton,
Massachusetts 01720, USA
Email: anshul.chadda@trebia.com
ROBERT D. RUSSELL
InterOperability
Laboratory
University
of New Hampshire
Durham,
New Hampshire 03824, USA
Email:
rdr @iol.unh.edu
NARENDRAN GANAPATHY
Pirus
Networks
43
Nagog Park
Acton,
Massachusetts 01720, USA
Email: naren@pirus.com
1 Introduction
In the last decade, there has been a demand in the computer industry to physically separate storage from the main computing system and to connect them with networking technology. The motivation for this is the desire for higher performance and greater scalability in Storage Networking. There are two approaches in the industry to support storage across networks: Network Attached Storage (NAS) and Storage Area Networks (SAN).
NAS intercepts the communication between application (host) and storage at a fairly high level, because the application typically accesses the remote storage via a special file system that in turn utilizes a standard network protocol stack. The unit of access is a file managed by the NAS. A NAS must deal with issues of security, consistency, integrity, etc. at the level of a complete file. The most common example of a NAS is Sun’s Network File System (NFS) [8] which is almost universally supported by all manufacturers. Some of the advantages of NFS are that it is easily installable and is affordable. One of the disadvantages is that the storage access is limited through the Server. Direct access to storage devices is not possible. The other disadvantage is that the I/O performance is limited by the speed of a single NAS server’s ability to handle I/O requests from different application clients.
SAN intercepts the communication between application (host) and storage at a fairly low level, because the host views the remote storage as a device that is accessed over an I/O channel capable of long-distance transfers. The unit of access is a ‘raw’ storage block managed by the SAN. In this model, the remote server system is typically much less sophisticated than for a NAS, because it only has to implement that part of the network protocol stack necessary to communicate with clients. A SAN must deal with issues of security, consistency, integrity, etc. at the level of a single block, not a whole file as in a NAS.
The Small Computer System Interface (SCSI) is a ubiquitous and popular disk technology that supports block level access [10]. The major limitation of SCSI is the length of the SCSI bus (25 m). Several protocols have been proposed to extend the length of the SCSI bus: Fiber Channel (FC) [9], and Internet SCSI (iSCSI). Although FC fits into the requirement of high performance, it has limited scalability as it needs a specialized network of storage devices.
iSCSI is a Session Layer Protocol that supports SCSI on top of TCP/IP/Ethernet networks and hence enhances scalability of SANs. Implementing SCSI over TCP for IP storage leverages existing network hardware, software, and technical know-how. SCSI over TCP will enable the use of Gigabit Ethernet, a proven industry standard, as an infrastructure for storage-area networks (SAN). TCP/IP and Ethernet are dominant technologies in networking, and we see this trend continuing with SANs.
In this paper, we discuss the design, implemention, and evaluation of the iSCSI protocol. As an overview, the iSCSI protocol gets the SCSI I/O requests in the kernel on the host (application) and transfers it over the TCP/IP network to the target (device). The iSCSI low-level driver is designed and implemented for the initiator to support the latest protocol draft. An existing target emulator was modified and extended to support the additional features specified in the latest iSCSI draft. The evaluation of the iSCSI protocol involves basic performance analysis using software tracing facilities in the Linux kernel. The results suggest the optimum performance parameter values for I/O operation over generic TCP/IP/Ethernet Networks[1].
The rest of the paper is organized as follows. Section 2 describes the approach taken to perform this study on a software implementation of the iSCSI protocol using the Linux operating system. Section 3 gives a brief summary of the features of iSCSI. Section 4 describes a tool used to take precise measurements of Linux kernel operations. Section 5 describes the design and implementation of the Linux kernel module we developed. Section 6 describes our performance experiments and the observed results. Section 7 draws some conclusions and section 8 discusses future work.
2 SAN Approach for this study
Block level access to a target disk
connected through a TCP/IP/Gigabit Ethernet network would require TCP/IP
implementation in the target hardware in addition to implementation of the
iSCSI Protocol. Hardware implementation of Network Protocols like TCP/IP is an
intricate process by itself. An alternate approach, followed in this paper, is
to emulate the target in software on a remote system as shown in Fig. 1.
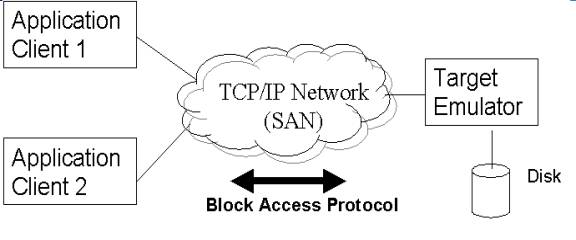
Fig 1 Our Approach to Storage Area Network (SAN).
Efforts to increase scalability of
SCSI have increased the number of components involved in the Operating System
(Fig. 2). The transition from the classic SCSI approach to our approach is
discussed as follows:
·
The classic
SCSI approach is to have a SCSI Host Bus Adapter (HBA) accessing a SCSI disk (target) connected by a SCSI
Bus(Fig. 2a). The READ/WRITE requests generated by the user go through the Filesystem
to be resolved into SCSI Commands, Messages, and Responses. The SCSI requests
are passed to the HBA that accesses the
SCSI disk (target).
·
In our approach (Fig. 2b), the extra
components added are as follows:
o SAN Initiator and Target subsystems to
support the Session Protocols.
o Network Stack to support TCP/IP.
o Transport Network to communicate between the
Initiator and the Target Emulator
An existing SCSI target emulator [5]
was extended to support the latest draft of iSCSI protocol.
The operating system used is Linux.
In the Linux Operating system, the SCSI Layer is called the SCSI
Mid-Level(SML). The driver that supports SCSI protocol is called a Low-level
Driver (LLD). The iSCSI low-level driver (explained in Section 5) is
implemented to support the latest specification of the iSCSI draft, which is
discussed next.
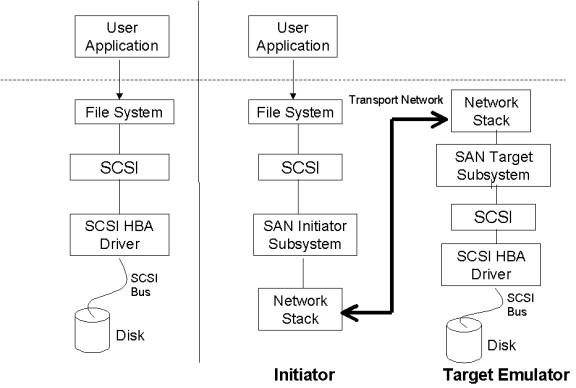
(2a) (2b)
Fig 2 Components involved to support SCSI.
3 Internet SCSI (iSCSI)
The Internet SCSI (iSCSI) is a combined effort of a group of companies including IBM, Cisco Systems, Hewlett-Packard, SANGate, Adaptec, and Quantum. It is currently being developed under the aegis of the Internet Engineering Task Force. The protocol is on course to become an RFC and is currently an Internet Draft at version 19 [7]. The iSCSI protocol is a session layer protocol that assumes the presence of a reliable, connection- oriented transport layer protocol like TCP. It includes considerations for naming, TCP connection establishment, security, and authentication.
Communication between an Initiator and a Target occurs over one or more TCP connections. The TCP connections are used for SCSI commands, task management commands, data, protocol parameters, and control messages within an iSCSI Protocol Data Unit (iSCSI PDU). All related TCP connections between the same initiator and the target are considered to belong to a session (referenced by a session ID).
The iSCSI protocol supports command, status, and data numbering schemes which are needed during flow control, error handling, and error recovery. Command numbering is session wide and is used for ordered command delivery over multiple connections. It can also be used as a mechanism for command flow control over a session. Status numbering is per connection and is used to enable recovery in case of connection failure. Data numbering is per command and is meant to reduce the amount of memory needed by a target sending unrecoverable data for command retry. The three numbering schemes are as follows: CmdSN (Command Sequence Number), StatSN (Status Sequence Number), and DataSN (Data Sequence Number).
The iSCSI protocol deals with error recovery in case of protocol errors. It is assumed that iSCSI in conjunction with SCSI is able to keep enough information to be able to rebuild the command Protocol Data Unit (PDU), and that outgoing data is available in host memory for retransmission while the command is outstanding. It is also assumed that at a target, iSCSI and specialized TCP implementations are able to recover unacknowledged data from a closing connection or, alternatively, the target has the means to re-read the data from a device server. The transmission of, or absence thereof, status and sense information is used by the initiator to decide which commands have been executed or not.
Other issues concerning configurable options, security, error handling, and recovery are also addressed in the latest iSCSI draft.
4 Fast Kernel Tracing-Performance Measurement Tool
Fast Kernel tracing (FKT) is a method for obtaining a precise, time-stamped trace of the dynamic activities of kernel-level code[6]. The basic motivation being that it is extremely difficult to know exactly what an operating system is doing, especially in a networked environment.
The method consists of placing special software “probe” macros at various locations in the kernel source code. Placement of probes is controlled by the kernel programmer, as is the information recorded by the probe. Typically, one probe is placed at the entry to, and another at the exit from, every kernel function of interest to the programmer. The entry probe can record the parameters passed into the function, and the exit probe can record the function’s return value. If any changes are made regarding any probe (added, deleted or relocated), the kernel must be rebuilt and rebooted.
Probes record data and store it into a large buffer in the kernel. The buffer size available is limited and can get filled up before tracing is finished. Currently, probing is suspended whenever the buffer gets filled. After recording has been finished, a user-level program can obtain a copy of the probe data from the kernel buffer and write it to a file for later off-line analysis. There are permanently assigned probes that record every IRQ, exception, system call, and task switch handled by the kernel during the sampling interval. This data, together with that from the programmer assigned codes, can be presented in the form of the actual traces themselves, with time spent in each step of the trace. However, it is easy to obtain more detailed data, such as the minimum, maximum, and average amounts of time spent in each kernel function, the nesting characteristics of the functions, etc.
5 iSCSI Initiator Design And Implementation
In this section, we give an overview of the iSCSI Low-Level Driver
design. When the iSCSI low-level driver (LLD) is loaded, it registers itself
with the SCSI Mid-level (SML). The iSCSI LLD provides to the SML a list of
functions that enable the SML to pass commands to the iSCSI LLD.
The ‘iscsi_config’ configuration tool [3] uses the Linux /proc filesystem
interface to communicate configuration information to the LLD module in order
to cause it to make a connection to a target. After a TCP connection is made,
the LLD enters the Login Phase and does Text Parameter negotiation. After
successful Login Phase Parameter Negotiation, the iSCSI LLD spawns two
threads. A transmit thread (tx_thread) is started that can transmit, to the target, iSCSI PDUs of type ‘SCSI
Command’, ‘Task Management Command’ and ‘SCSI DataOut’. A receive thread (rx_thread) is started that can receive, from the target, iSCSI PDUs of type ‘SCSI
Response’, ‘Task Management Response’, ‘SCSI Data-In’, ‘Ready to Transfer’, and
‘Reject’.
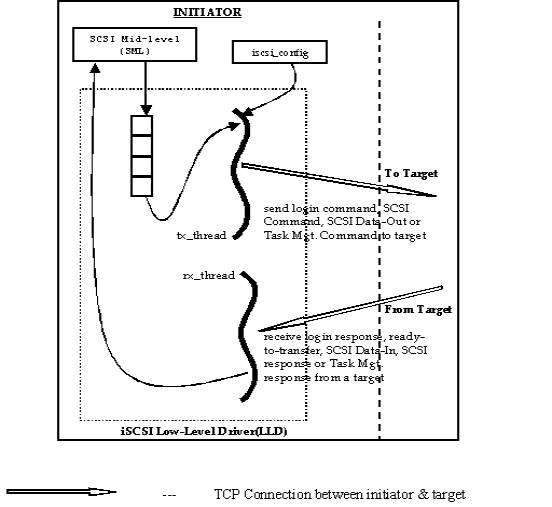
Fig. 3 iSCSI Low-Level driver (LLD) Design.
After starting the two threads (Fig. 3), the iSCSI LLD enters the Full
Feature Phase and notifies the SML that a target with a particular target
number is accessible for I/O operations. The SML passes the SCSI commands
INQUIRY, TEST_UNIT_READY, DISK_CAPACITY, and READ (to read the superblock of
the target/disk) to the iSCSI LLD. The iSCSI LLD is able to get all the
relevant information from the Target as it has an established TCP connection
and is in the Full Feature Phase of the iSCSI Protocol.
When a new SCSI command is passed to the LLD, the LLD sets up the TCP
buffers to send the iSCSI PDU of type ‘SCSI Command’. The tx_thread is woken up to send the PDU to the target. Data handling for any SCSI
Command by the LLD depends on the operation involved: READ or WRITE. We discuss
data handling by the iSCSI LLD in two separate cases:
·
For a READ
request, the LLD receives the ‘SCSI Data-In’ PDUs through the rx_thread. It fills the data buffers provided by the SML.
·
For a WRITE
request, the LLD sends the ‘SCSI Data-Out’ PDUs as ‘Unsolicited Data’ or in
response to ‘Ready to Transfer’ PDUs received by the rx_thread from the target.
After all the Data has been transferred between the initiator and the
target, the iSCSI LLD waits for a iSCSI ‘SCSI Response’ PDU to be received from
the target. On receipt of iSCSI ‘SCSI Response’ PDU in the rx_thread, the LLD delivers status and sense data, if present, to the SML. The LLD
then frees up the resources allocated for the particular SCSI command.
The iSCSI LLD design supports multiple sessions and multiple connections
within a session as specified by the iSCSI protocol. A separate rx_thread receives iSCSI PDUs from each connection in a session from the target. A
single tx_thread is used to send iSCSI PDUs on all
connections in a session to the target.
When there is a huge amount of data to be written or read, the SML passes
an array of data buffer pointers (instead of single data buffer pointer) to the
iSCSI LLD, which is referred to as ‘scatter-gather list’. The scatter-gather
list is used when the requested amount of memory is not available contiguously
to the SML. The iSCSI LLD can handle a scatter-gather list, that is, if it gets
an array of data pointers, it will pass all the pointers to the TCP/IP socket
functions appropriately.
6
Performance
Analysis
This section describes the Test Set-Up Details for doing performance analysis. The Performance Metrics (variables to quantify performance) and Variables (parameters that affect performance) are discussed next. The Performance Analysis for iSCSI Protocol is discussed in the final subsection.
6.1 Test Set-Up
The test set-up involves two
computer systems: an initiator and a target. The two computer systems were PCs
running the Linux operating system. The initiator and target emulator code are
dynamically loaded kernel modules.
CPUs
·
Initiator System: Intel Pentium III, 455 MHz Processor, 128 Mbytes RAM.
·
Target System: Intel Pentium III, 667 MHz Processor, 128 Mbytes RAM.
Ethernet Technologies
The tests were run on Fast Ethernet and Gigabit Ethernet as two Link
Layer Technologies. The following are the NICs that are used for each
technology.
·
Fast Ethernet
Card: 3 Com Vortex
Driver: linux/drivers/net/3c59x.c
V1.102.2.38H 9/02/00 Donald Becker and others
·
Gigabit
Ethernet
Card: 3 Com Acenic
Driver:
linux/drivers/net/acenic.c
V0.33a 08/16/99 Jes Sorensen
Fiber_Channel Technologies
The Fiber Channel driver for the Host Bus Adapter (HBA) is used to access a Fiber Channel on the target emulator system. The hba card is from Qlogic Corporation ISP2200 A and the driver is linux/drivers/net/qlogicfc.c.
Version of Linux Operating System
2.4.0-test9
6.2 Performance Metrics
The Performance metrics give a measure of how well or how poorly a system is behaving. The common performance Metrics are as follows:
Bandwidth
The bandwidth measurement gives the
data transfer rate between the initiator and the target during Disk I/O
operation. This metric is measured for the iSCSI Protocol, as discussed in
Section 6.4.
CPU utilization
CPU utilization is an important
parameter that should be monitored on the initiator and the target side during
data transfer. The measurement unit gives the percentage of CPU cycles used by
different routines in the Operating System while performing Disk I/O operation.
This metric is measured for the iSCSI Protocol, as discussed in Section 6.4.
Latency
The latency measurement gives the
delay (in secs) to perform any request given by the initiator. In other words,
it gives the time required to perform any I/O operation requested by the
initiator. This metric is not measured in this paper.
6.3 Performance Variables
The performance variables are the
parameters that affect the performance metrics. This section lists the
performance parameters and elaborates on the effect of each parameter on the
performance metrics.
Target Block size
The block size is the portion, or
sector, of a disk that stores a group of bytes that must all be read or written
together. The target specifies the block size for data storage at the time of
inquiry by the initiator. Disk I/O rate will be affected by the number of
blocks transferred per unit time which in turn depends on the block size. The
block size in the target emulator, which is used in testing the iSCSI
Implementation, is a constant that can be changed at compile time.
Link Layer Protocol
The underlying Link Layer technology
used is Ethernet. The performance tests can be performed on the different
Ethernet interfaces: Fast Ethernet (100 Mbps) and Gigabit Ethernet (1 Gbps).
The performance metrics should be affected by the link layer interconnect used.
The standard packet size for Ethernet, Fast Ethernet, and Gigabit
Ethernet is 1500 bytes. However, there is a non-standard option of increasing
the packet size to 9000 bytes when the Gigabit Ethernet interface is brought up
on the Linux O/S. The Ethernet packet
size is changed to analyze the effect on Performance metrics.
I/O on Target Side
The following possibilities are considered for I/O on the target side:
- I/O to and from memory directly – this will test the iSCSI layer protocol itself. This is the target mode used for most of the performance tests in this Chapter.
- I/O to and from a file – this will test the performance of SCSI over the interconnect in question.
- I/O to and from a disk without going through the file system– this will test the performance of the protocol in a real world system.
Size of the Data PDU in the Session Protocol
When data is exchanged between the Initiator and the Target for the iSCSI
Protocol, the actual READ/WRITE Data is transferred in iSCSI Data PDUs. The
iSCSI Protocol provides an option of changing the Maximum Data PDU Length for
any I/O operation. A change in Maximum Data PDU Length for the iSCSI Protocol
can affect the Performance Metrics, as discussed in Section 6.4.
6.4 Performance Results for iSCSI
The performance tests are performed for WRITE requests that transfer data from the initiator to the target. The WRITE operation requested by the user application on the initiator bypasses the filesystem on the initiator system. This is done to avoid buffering, caching effect and possible asynchronous I/O operation due to the filesystem present on the initiator system. In order to measure the speed of the transport network between the initiator and the target, the data is written/read out of memory on the target side.
6.4.1 Effect of Target Block Size on Bandwidth for iSCSI
In Fig. 4, the WRITE Request size plotted on the X-axis represents the amount of WRITE Data (in MB) requested by a user application on the initiator to be sent from the initiator to the target emulator. The Data Rate (in MB/s) recorded is plotted on the Y-axis. Each bandwidth value plotted on the Y-axis is the average value for 10 sample runs.
The bandwidth increases from 18.5 MB/s for 512 KB block size to 21 MB/s for 4096 KB block size (Fig. 4). The biggest increase occurs when going from 512 to 1024 byte blocks and almost no increase occurs for block sizes greater than 2048 bytes. The improvement in bandwidth can be attributed to the fact that the block size increment increases the number of bytes per I/O request passed to the iSCSI Low-Level Driver (LLD). This decreases the number of I/O requests that SCSI Mid-Level (SML) has to pass to the iSCSI LLD. It can be inferred that the number of I/O requests overhead is a major contributor to the cost.
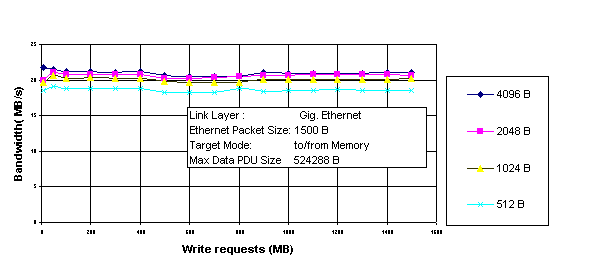
Fig. 4 Effect of Target Block Size on Bandwidth for iSCSI.
The lines in the above chart are obtained when the Nagle Algorithm [4] is
turned OFF on both the initiator and the target emulator. When the Nagle Algorithm was ON,
the bandwidth for the WRITE operation (using a blocksize of 4096 bytes) was
observed to be only 3 MB/s. The Nagle Algorithm delays the delivery of
small iSCSI PDUs until a TCP sender either fills a maximum sized segment or
receives an acknowledgment from the receiver, which may be delayed until a
receiver timeout occurs that is about 200 msec on Linux. Turning the Nagle Algorithm OFF avoids this delay and
increases the bandwidth from 3 to 21 MB/s for a blocksize of 4096 bytes.
CPU Utilization for Initiator
system with Target Block Size=4096 bytes
The FKT software probes are
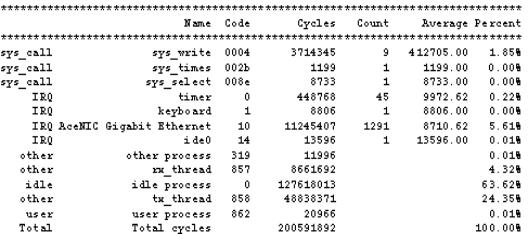
used to calculate the percentage CPU utilization on the initiator system. Table
1 gives the name of the various IRQs, system calls and routines that are called
during WRITE Data test explained in Section 6.4.1. The Performance Parameter
values corresponding to Table 1 are as follows:
Block size:
4096 B
Link Layer : Gig.
Ethernet
Ethernet Packet
Size
1500 B
Target Mode: to/from Memory
Max PDU Size: 524288 bytes
The column ‘code’ gives the probe
identification code for the probes present in those routines. The ‘Cycles’
column lists the total number of cycles that are spent in each routine. ‘Count’
gives the number of times the routines are called. The average number of cycles
(Cycles/Count) that are spent in each routine are shown in the column
‘Average’. Finally, the last column shows the percentage of time spent in each
routine.
Table 1 indicates that most of the
cycles are spent in the idle process (63.62%). The idle process time can be
attributed to the time spent in NIC processing [2] (on both initiator and
target emulator) and in I/O request processing by the Operating System in the
Target Emulator. The Target Emulator, when processing the I/O request from the
initiator, involves the network stack including TCP, IP, and the Gigabit
Ethernet driver in the Linux Operating System. The other components involved
are the SCSI Target Mid-Level (STML) and the iSCSI Front-End Target Driver
(FETD).
The percentage CPU utilization for the tx_thread (24.35%) is more than that for the rx_thread (4.32%) because for a WRITE operation, data is transferred from the initiator to the target which involves calls to the tx_thread. The rx_thread involvement during a WRITE operation is much less.
Processing of the Gigabit Ethernet
card interrupts takes 6.23%. The sys_write() system call
takes 1.85% of the CPU. Other processes running on the initiator take
0.25% of the time during WRITE operation.
The total percentage CPU utilization
on the initiator system is calculated to be 100-63.62=36.38%.
Table 1 Analysis Table
produced by fkt_print for iSCSI Low-Level driver.
CPU utilization comparison
The Percentage CPU utilization on the initiator system decreases from 44.62% to 36.38% when the Target Block Size increases from 512 B to 4096 B. Percentage CPU utilization on the initiator system decreases with an increase in the Target Block size. This is because the initiator allocates the SCSI scatter-gather buffers such that each buffer is the same size as the Target Block Size. The initiator has to allocate and process more buffers if the Target Block Size is small (for writing a constant amount of data to the target). This, in turn, utilizes more CPU cycles on the initiator.
6.4.2 Effect of Ethernet Link Speed on Bandwidth for iSCSI
As shown in Fig. 5, on a Fast Ethernet Link, the bandwidth for a WRITE operation is 10.2 MB/s, using 86% of the maximum bandwidth possible at 11.9 MB/s. On a Gigabit Ethernet link, the bandwidth for a WRITE operation is 21 MB/s, using only 19% of the maximum bandwidth possible at 119 MB/s. Each bandwidth value plotted on the Y-axis is the average value for 3 sample runs.
It can be concluded that for I/O operations, the Link Speed in Fast Ethernet Connection is a limiting factor, because increasing the link speed results in an absolute increase in bandwidth. However, this is not the case with Gigabit Ethernet link - the bottleneck in this case must be some other involved components, since the absolute increase in available bandwidth is actually accompanied by a significant decrease in percentage bandwidth utilization.

Fig. 5 Effect of Ethernet Link Speed on Bandwidth for iSCSI
.
CPU utilization comparison
The Percentage CPU utilization on the initiator system increases from 27.77% to 36.38% when the Ethernet Link speed increases from 100 Mbps to 1000 Mbps. The percentage CPU utilization on the initiator system for Fast Ethernet is comparatively less than that for Gigabit Ethernet. The reason for this can be that the available bandwidth on Fast Ethernet link is utilized completely (86% of maximum theoretical bandwidth), so the initiator CPU is idle for more time compared to that for Gigabit Ethernet Link. The Link speed in Fast Ethernet is the bottleneck in doing WRITE I/O operations.
6.4.3 Effect of Ethernet Packet Size on Bandwidth for iSCSI
As shown in Fig. 6, the Bandwidth increases from 21 to 30 MB/s when the Ethernet Packet size increases from 1500 to 9000 bytes on both the initiator and the target systems. Each bandwidth value plotted on the Y-axis is the average value for 3 sample runs.
CPU utilization comparison
The Percentage CPU utilization on the initiator system decreases from 36.38%
to 35.67% when the Ethernet Packet Size increases from 1500 bytes to 9000
bytes. TCP allocates buffers whose
maximum size is equivalent to the Ethernet Maximum Payload Size. The number of
TCP buffers allocated, for a given amount of data, decreases when the Ethernet
Packet size increases (from 1500 to 9000 bytes) and this in turn reduces the
TCP processing on the initiator system.
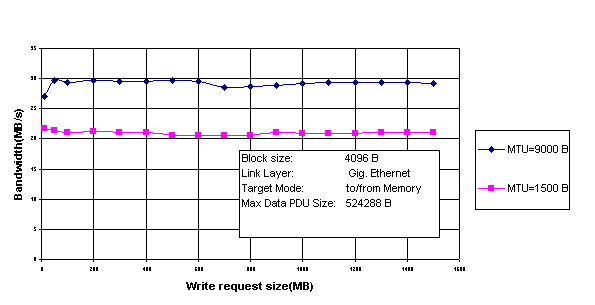
Fig. 6 Effect of Ethernet Packet
Size on Bandwidth for iSCSI.
6.4.4 Effect of Max PDU Size on Bandwidth for iSCSI
The Maximum PDU size for the iSCSI Protocol was changed to see the effect on Bandwidth for the WRITE operation. When the Maximum PDU size is decreased from 524288 bytes to 1024 bytes, the bandwidth decreases from 21 MB/s to 19 MB/s (Fig. 7). Each bandwidth value plotted on the Y-axis is the average value for 3 sample runs. When the maximum Data PDU size is decreased, the number of iSCSI PDUs required to transfer same amount of data increases. It is due to this reason that the bandwidth decreases when the Maximum PDU size decreases.

Fig.
7 Effect of Max Data PDU Size on Bandwidth for iSCSI
CPU utilization comparison
The Percentage CPU utilization on
the initiator system decreased from 44.26% to 36.38% when the max PDU size
increased from 1024 to 524288 bytes. When the Maximum PDU size is 1024
bytes, the initiator needs to send more
iSCSI PDUs than when the Max PDU size is 524288 bytes. So, more CPU cycles are
consumed when the initiator has Maximum PDU size set to 1024 bytes.
7
Conclusions
Design and Implementation
This paper presents a general architecture for implementing Session Layer Protocols on the initiator. An existing target emulator was modified and extended to support the additional features specified in the latest iSCSI draft. The iSCSI initiator follows an asynchronous model. The iSCSI LLD can handle multiple commands at a given time. Two threads, one for receiving and the other for transmitting, are used to communicate with the target. The iSCSI initiator and target are implemented as dynamically loadable modules for the linux kernel. The latest iSCSI initiator and target emulator implementations (for iSCSI draft 18/19) are available from the iSCSI Consortium, IOL web-page under “iSCSI Downloads” (http://www.iol.unh.edu/consortiums/iscsi).
Performance Analysis
The Performance Parameters that affect the bandwidth for WRITE operations are: Block Size, Ethernet Link Speed, Ethernet Packet Size and Maximum PDU size for the iSCSI Protocol.
On a Fast Ethernet Link, the recorded bandwidth for WRITE operation is 10 MB/s, using 86% of the maximum bandwidth possible at 11.2 MB/s. On a Gigabit Ethernet link, the absolute bandwidth increased to 21 MB/s but the percentage bandwidth utilization is only 19% of the maximum possible bandwidth at 112 MB/s.
The Nagle Algorithm should be turned OFF when doing READ/WRITE operations in order to gain high bandwidth and low latency.
8 Future Work
The
performance analysis is done only on the initiator system in this paper. The
target system should also be analyzed with the software probes to find out the
bottlenecks affecting the performance metrics. Also, a similar analysis should
be done for READ operations (on both the initiator and the target emulator).
A
detailed analysis is required to be done for each network stack component
involved in the I/O operations. The latency measurements, not performed in this
paper, should be done for each component to find the actual bottlenecks
affecting performance.
From
the performance analysis section, it is observed that the percentage CPU
utilization on the initiator is low. Also, the bandwidth utilization on Gigabit
Ethernet link is just 19%. It is suggested to run multiple simultaneous
applications on the initiator system in an attempt to increase the percentage
CPU utilization
of the systems and the available bandwidth on the wire. Other features of the
iSCSI protocol should also be tested and analyzed for their effect on
performance. These include multiple Logical Units per session, multiple
connections per session, and multiple outstanding Ready-to-Transfer PDUs per
WRITE command.
The
performance analysis should also be done on Gigabit Ethernet NICs from different
manufacturers to compare NIC processing time on each NIC.
Finally, hardware implementation for TCP/IP and iSCSI, if available, should be
tested and compared with Fibre Channel technology for bandwidth, latency and
CPU utilization.
References
- Chadda A. Design, Implementation, and Performance
Analysis of Session Layer Protocols for SCSI over TCP/IP. M.S.
Thesis, Dept. of Computer Science, University of New Hampshire, December
2001.
- Chavan M. Performance Analysis of Network
Protocol Stacks Using Software Probes. M.S. Thesis, Dept. of Computer
Science, University of New Hampshire, September 2000.
- Ganapathy N. Conformance testing, Design, and
Implementation of the login phase of iSCSI (SCSI over TCP/IP). M.S.
Thesis, Dept. of Computer Science, University of New Hampshire, December
2001.
- Nagle J. Congestion
Control in IP/TCP Internetworks. IETF RFC 896, http://www.ietf.org/rfc/rfc0896.txt?number=896,
January 1984.
- Palekar A. Design
and Implementation of the SCSI Target Mid-level for the Linux Operating
System. M.S. Thesis, Dept. of Computer Science, University of New
Hampshire, May 2001.
- Russell R.D.
FKT: Fast Kernel Tracing. Technical Report 00-02, Dept.of Computer
Science, University of New Hampshire, March 2000.
- Satran J. et al.
Internet SCSI (iSCSI). IETF Internet Draft, November 2002; http://www.haifa.il.ibm.com/satran/ips/draft-ietf-ips-iscsi-19.txt
- Shepler S.,
Callaghan B., Robinson D., Thurlow R., Beame C., Eisler M., and Noveck D. NFS
version 4 Protocol. IETF RFC 3010, December 2000.
- Snively R. et. al.
Information Technology – dpANS Fiber Channel Protocol for SCSI (SCSI-FCP).
Proposed Draft (ANSI X2.269-1995, Revision 12), December 1995.
- Weber R. et. al.
Information Technology - SCSI Architecture Model –2 (SAM-2).
Working Draft (T10 Project 1157D, Revision 15), November 2000.
Biography
Anshul Chadda (anshul.chadda@trebia.com) received his Master’s Degree from University of New Hampshire, Durham, NH in Computer Science in December 2001. This paper is based on the thesis work submitted in fulfillment of his Master’s degree. He is currently an employee of Trebia Networks, Acton, MA.
Ashish Palekar (ashish.palekar@trebia.com) received his Master’s Degree from University of New Hampshire, Durham, NH in Computer Science in May 2001. He is currently an employee of Trebia Networks, Acton, MA.
Narendran Ganapathy (naren@pirus.com) received his Master’s Degree from University of New Hampshire, Durham, NH in Computer Science in December 2001. He is currently an employee of Pirus Networks, Acton, MA.
Prof. R.D.Russell (rdr@cs.unh.edu) is an Associate Professor of Computer Science at the University of New Hampshire, Durham, NH. His research interests include: Storage Area Networks, Reliable high-speed protocols for clusters, Fine-grained performance analysis for clusters and Network management using constraints.